
Introduction
At Acadeva, we set out to solve a problem that exists across nearly every academic environment. It is not the absence of learning materials, but the absence of meaningful organization. Academic resources such as textbooks, lecture notes, and past questions are widely available, yet they are often scattered across platforms, loosely categorized, and difficult to navigate in a way that aligns with how students actually study.
Our early focus was on aggregation and search. We invested significant effort into gathering academic resources and making them searchable within the platform. This approach improved access, but it did not fully solve the problem. Students could find materials if they searched for them, but the experience lacked structure. Discovery was still dependent on effort rather than design.
As usage increased, it became clear that access without organization leads to friction. Students expect to enter a study environment and immediately see materials relevant to their courses. When that expectation is not met, engagement drops.

Angel
Limitations of User-Driven Organization
Our initial organizational model relied heavily on user input. When uploading resources, users were required to assign metadata such as department, institution, and course associations. This approach assumed that contributors would consistently provide accurate and complete information.
In practice, this assumption did not hold.
Users often misclassified materials, skipped important fields, or selected categories that did not reflect the actual scope of the resource. Even when the metadata was correct, it introduced unnecessary friction into the upload process. Over time, inconsistencies accumulated, reducing the overall reliability of the system.
A more subtle limitation also emerged. Academic resources are not always confined to a single department or course. Students frequently collect materials that are useful across disciplines. A textbook uploaded by a student in one department may be highly relevant to students in another. The system, however, treated each resource as belonging to a fixed category defined by the uploader.
This created a mismatch between resource ownership and resource relevance.
The impact of these limitations became evident in user behavior. Students would complete onboarding, enter their study space, and find little or no relevant content. In many cases, the resources existed within the platform but were not surfaced appropriately. Even when users uploaded their own materials, incorrect metadata prevented those resources from appearing in their study view.
Growth, Engagement, and the Need for Structure
During examination periods, the platform experienced significant growth. This was driven largely by the adoption of our AI-powered quiz generation feature, which provided immediate value to students preparing for exams.
However, this growth revealed a deeper issue. While usage spiked during exams, retention remained low throughout the rest of the semester. Students engaged with the platform when they had urgent needs, but did not remain active over time.
This pattern highlighted a gap between utility and experience. The platform provided useful tools, but it did not yet offer a structured academic environment that students could rely on consistently.
We concluded that improving organization was not just a feature enhancement. It was essential to long-term engagement.
Towards a Course-Centric Model
To address these challenges, we began exploring automated methods of organizing academic resources. This led to the development of an internal system known as acadeva-magic-1, designed to classify study materials and map them to relevant courses.
This approach marked a shift from user-defined organization to system-driven classification. Instead of relying on metadata provided at upload, the system would analyze the content of each resource and determine where it belonged.
Early results were promising, but they revealed a critical dependency. Effective classification requires a reliable understanding of the target structure. In this case, that structure is the set of courses across academic programs.
This raised an important question. Where do we obtain an accurate and comprehensive list of courses?
Building the Course Dataset
Constructing the course dataset became one of the most demanding aspects of this work. It required gathering information across institutions, mapping academic programs, and identifying the courses that define each program.
This process involved:
- Collecting program structures from multiple universities
- Standardizing course representations across institutions
- Continuously updating the dataset as new courses are discovered
Even after assembling an initial dataset, we designed the system to remain adaptive. New courses can be introduced as they are identified, and the system is able to incorporate them without requiring a complete restructuring.
We also introduced a method we refer to as reverse indexing. Instead of starting with a resource and assigning it to a course, we begin with the course and identify all resources that are relevant to it. This approach improves coverage and ensures that materials are not overlooked due to incomplete initial classification.
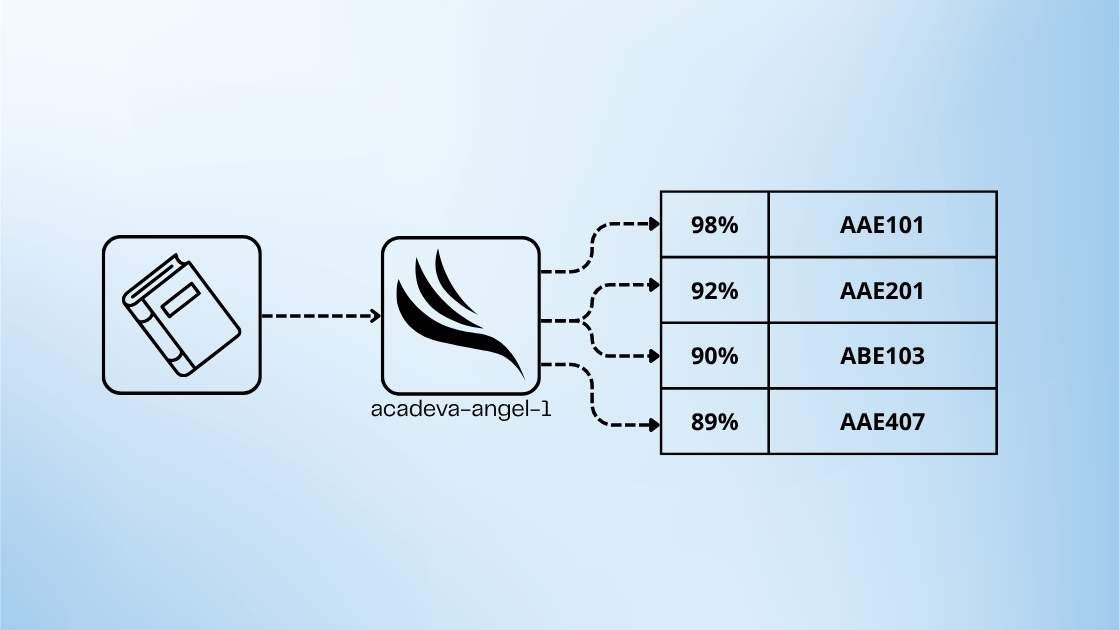
Acadeva-Angel-1: A Course-Centric Classification System
With the dataset in place, we developed a more advanced system, Acadeva-angel-1, designed to classify and organize resources at scale.
The system was built with three primary considerations:
- Accuracy of classification
- Efficiency of processing
- Cost-effectiveness at scale
Accuracy is the most critical of these factors. In an academic context, incorrect classification reduces trust in the platform. A single misplaced resource can affect how users perceive the reliability of the entire system.
We therefore define quality in terms of relevance, and relevance in terms of accuracy.
Performance was also a key consideration. Academic resources are often large and frequently exist as scanned documents. Acadeva-angel-1 is capable of processing scanned PDFs, including those requiring Optical Character Recognition, at a rate of approximately 15 seconds per 1000 pages.
This level of performance ensures that new materials can be integrated into the system quickly, maintaining a responsive and up-to-date experience for users.
Acadeva-Angel-1 processing workflow
Deployment and Validation
Once the system reached a stable state, we applied it to a large subset of our dataset, including over 2000 textbooks. The classification results were evaluated through a combination of automated checks and manual review.
Human-in-the-loop validation played an important role in this phase. While the system achieved strong performance, human oversight ensured that edge cases and ambiguities were addressed. This combination of automation and review allowed us to maintain a high standard of quality.
Following this validation process, we extended the system to include additional resource types such as lecture notes and past examination questions. These materials were integrated into the same course-centric structure, creating a unified study environment.
Outcome and Impact
The transition to a course-centric framework fundamentally changed the way students interact with Acadeva.
Resources are now organized around courses rather than arbitrary categories. Students can enter their study space and immediately access materials relevant to their academic context. Navigation is more intuitive, and discovery no longer depends on manual search.
This shift has led to:
- Improved discoverability of academic resources
- Increased consistency in user engagement
- Higher retention rates across the academic term
Students now experience the platform as a structured environment rather than a collection of tools. The system aligns more closely with how academic learning is organized in practice.
[Insert Image Placeholder: Current course-based study interface]
Ongoing Work
The system continues to evolve. Improvements are being made in several areas, including:
- Enhancing classification models for greater accuracy
- Reducing processing time for large documents
- Expanding the course dataset to cover more institutions and regions
- Maintaining continuous human validation to ensure quality
This work sits at the intersection of machine learning, system engineering, data structuring, and content management. Each component contributes to the overall goal of building a reliable and scalable academic infrastructure.
Conclusion
Organizing academic resources at scale requires more than aggregation and search. It requires a structure that reflects how students actually learn.
By moving from a user-dependent model to a course-centric framework, we have established a foundation for a more consistent and effective study experience. The system reduces friction, improves relevance, and supports sustained engagement over time.
This is an ongoing process, but it represents a clear step toward a more organized academic ecosystem. One where resources are not just available, but meaningfully arranged.
And after working through thousands of textbooks, one thing is certain. Passing exams may be hard, but organizing everything needed to pass them is a completely different level of difficulty.